Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
Abstract
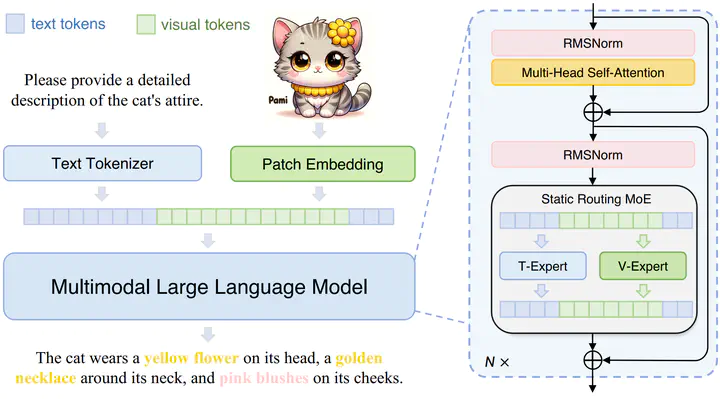
The rapid advancement of Large Language Models (LLMs) has led to an influx of efforts to extend their capabilities to multimodal tasks. Among them, growing attention has been focused on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. Despite the structural simplicity and deployment-friendliness, training a monolithic MLLM with promising performance still remains challenging. In particular, the popular approaches adopt continuous pre-training to extend a pre-trained LLM to a monolithic MLLM, which suffers from catastrophic forgetting and leads to performance degeneration. In this paper, we aim to overcome this limitation from the perspective of delta tuning. Specifically, our core idea is to embed visual parameters into a pre-trained LLM, thereby incrementally learning visual knowledge from massive data via delta tuning, i.e., freezing the LLM when optimizing the visual parameters. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results not only validate the superior performance of Mono-InternVL compared to the state-of-the-art MLLM on 6 multimodal benchmarks, e.g., +113 points over InternVL-1.5 on OCRBench, but also confirm its better deployment efficiency, with first token latency reduced by up to 67%.